
咨询热线
18888889999
18888889999
notice 网站公告
— 杏彩体育资讯 —
在人工智能深度学习领域,我们经常使用梯度下降法来完成神经网络的训练任务,梯度下降算法是当前神经网络的应用最为广泛的算法之一,但是这个算法存在一些问题,就是在梯度下降的过程中存在一些波动的情况,从而导致神经网络的训练过于缓慢,而神经网络的训练需要反复迭代才能找到最佳模型,所以神经网络的快速训练,能够帮助我们快速找到最好的神经网络模型。

如上图所示,最中心红点表示梯度最低点,也就是最终的目标点,而蓝色线表示梯度下降的过程,我们可以看到它从左到右不断逼近最低点,但是同时它也存在较大的上下波动的问题。所以它的训练速度会很缓慢,为了解决这个问题,我们需要让梯度下降的过程上下波动缓慢,而从左到右加快下降过程,这样我们的梯度下降才能更快的完成,从而加快神经网络的训练速度。
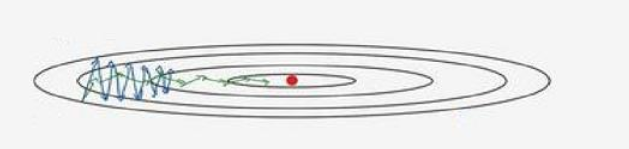
我们想要实现如上图绿色折线所示的梯度下将过程,如图所示,我们可以看出这个梯度下降过程,上下波动小,从左向右梯度下降迅速,这就是我们需要的,但是要想达到类似的功能,依靠传统的梯度下降算法是不能够完成的,所以需要使用Adam 优化算法,它是由动量梯度下降法和RMSprop 算法结合的。
动量梯度下降法,它的基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重。简单来说,我们需要做的就是在每次迭代中,确切来说在第t次迭代的过程中,和梯度下降算法一样首先计算出微分dW,db。然后我们需要计算的是vdW=βvdW+(1?β)dW,也就是 v=βv+(1?β)θt,然后我们重新赋值权重,W:=W?avdW ,同样b:=b?avdb ,这样就可以减缓梯度下降的幅度。
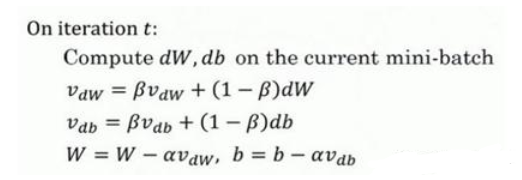
这里有两个超参数,超参数是学习率a以及参数β,β控制着指数加权平均数。最常用的值是0.9,因为0.9 是很棒的鲁棒性。
RMSprop 算法在第t次迭代中,该算法会照常计算当下 mini-batch 的微分dW,db,所以我们保留这个指数加权平均数,因此SdW=βSdW+ (1 ?β )dW2,这样做能够保留微分平方的加权平均数,同样Sdb=βSdb+ (1 ?β)db2,接着 RMSprop 会这样更新参数值。
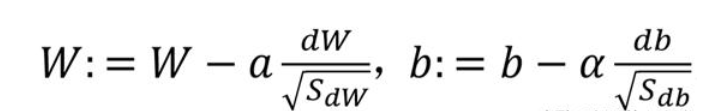
Adam=动量梯度下降+RMSprop ,我们只需要将这两种算法结合起来就形成了Adma优化算法,它具有动量梯度下降和RMSprop算法的优点。
使用 Adam 算法,首先你要初始化,vdW= 0,SdW= 0,vdb = 0,Sdb = 0,在第t次迭代中,你要计算微分,用当前的 mini-batch 计算dW,db,一般你会用 mini-batch 梯度下降法。
接下来计算 Momentum 指数加权平均数,所以vdW=β1vdW + (1 ?β1)dW,同样vdb=β1vdb+(1?β1)db。
接着你用 RMSprop 进行更新,即用不同的超参数β2,SdW= β2SdW + (1 ? β2)(dW)2,Sdb= β2Sdb+(1 ?β2)(db)2。
这就相当于相当于 Momentum 更新了超参数β1,RMSprop 更新了超参数β2。
最后更新权重

至此就完成了Adam 优化算法,这个算法已经证实比梯度下降算法能够加快神经网络的训练速度,为什么这个算法叫做 Adam?Adam 代表的是 Adaptive Moment Estimation,β1用于计算这个微分dW,它叫做第一矩,β2用来计算平方数的指数加权平均数(dW)2,它叫做第二矩,所以 Adam 的名字由此而来,但是大家都简称 Adam 优化算法。
如有需求请您联系我们!
地址:海南省海口市58号
电话:18888889999
手机:海南省海口市58号
Copyright © 2012-2018 首页-杏彩体育中国官方网站 版权所有 ICP备案编:琼ICP备88889999号




